In this post we explore a large collection of Sender Policy Framework (SPF) records to see what they might tell us about global email sending trust relationships and how they relate to email security providers. This is a fast follow-up to my previous post on Mining DNS MX Records for Fun and Profit.
Here is the methodology I devised for this (very similar to the previous post, but with new custom built tools):
- Collect a large sample of SPF records via DNS TXT lookups of popular domain names (and recursively resolving SPF “include” domains).
- Enrich SPF records with IP intelligence and useful metadata (including email security provider mappings)
- Analyze the enriched results.
Intro to Sender Policy Framework (SPF)
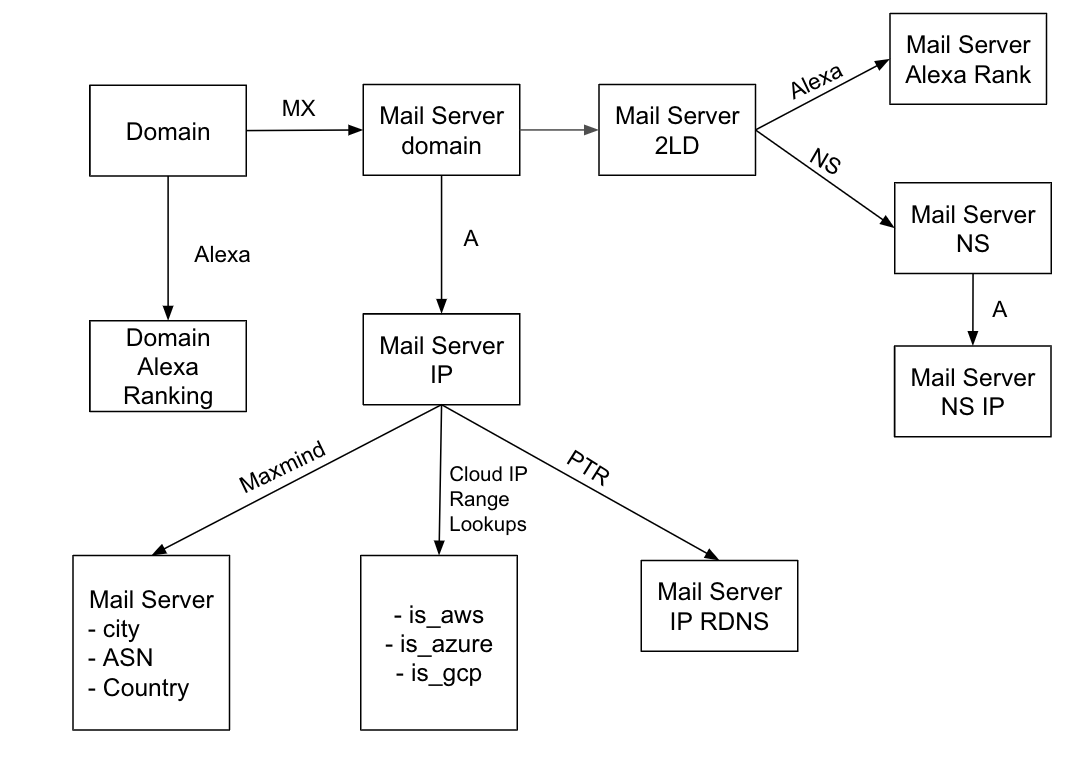
The Sender Policy Framework (SPF) enables domain name administrators to authorize hosts to use their domain names when sending email (i.e. in the “MAIL FROM” or “HELO” identities in SMTP). One of the goals of SPF is to limit spammer’s abilities to spoof email messages. SPF is limited and is usually used with DKIM and DMARC. SPF records are published using DNS TXT records. SPF compliant mail receivers use the published SPF records to test the authorization of sending Mail Transfer Agents (MTAs). SPF can be used to build complex policies around who can send email on whose behalf. Below is an example SPF record for Florida State University.
According to this SPF record 146.201.58.212, 146.201.58.213, 146.201.107.145, 146.201.107.249, 192.12.121.23, and 199.188.157.80 are allowed to send email purporting to be from fsu.edu. Also, the SPF records from spf.protection.outlook.com, _spf.qualtrics.com, spf.blackboardconnect.com, servers.mcsv.net, and _spf.mlsend.com should be retrieved and their policies applied as well. Below are the SPF records for each of these domains. As you can see they include more and more IPs/CIDRs as well as additional SPF includes.
As you can see, SPF forms a chain of trust between the domain owner and all the SPF policies included recursively (potentially crossing several different administrative boundaries). In this post I was hoping to explore this chain of trust at a large scale by collecting a large sample of SPF records and mining them.
Below are some useful resources for understanding SPF:
- RFC7208: Sender Policy Framework (SPF) for Authorizing Use of Domains in Email
- SPF Syntax Table - really useful guide for understanding SPF “mechanisms”.
Step One: Collection
For step one, I built a very crude useful SPF crawler that uses dig (optionally adnshost) to perform DNS TXT requests, parse out SPF records found, and then recursively follow the trail of SPF include records and perform TXT lookups against the included domains.
In order to seed the SPF crawler, I used the same domains I used in my previous blog post on mining MX records. I downloaded the Alexa top 1M domains, Quantcast top 1m domains (from WaybackMachine), Domcop Top 10m domains, Majestic Million Domains and Cisco Umbrella top 1m domains. I identified the registered domain using tldextract for each of these and then combined them into a single de-duplicated list. This resulted in ~8.3M unique domain names.
These domains were fed into my SPF crawler and then the results were collected, parsed, and then assembled. I ended up backing the SPF crawler with “dig” instead of “adnshost” this time since I found dig was more reliable, completing 23% more DNS requests in an experiment against the Fortune 1000 domains. Dig is single threaded, but I easily parallelized it using splits files and xargs and its performance ended up being good enough. See parallel_dig.sh for more details.
Below are a few simple commands as well as example output data collected with my SPF crawler applied to just one domain. As you can see, the assembled output for fsu.edu includes all the IPs and Netblocks from all the SPF includes that it links to, recursively.
Below is the same information, visualized as a network (and enriched with ASN info from Maxmind).
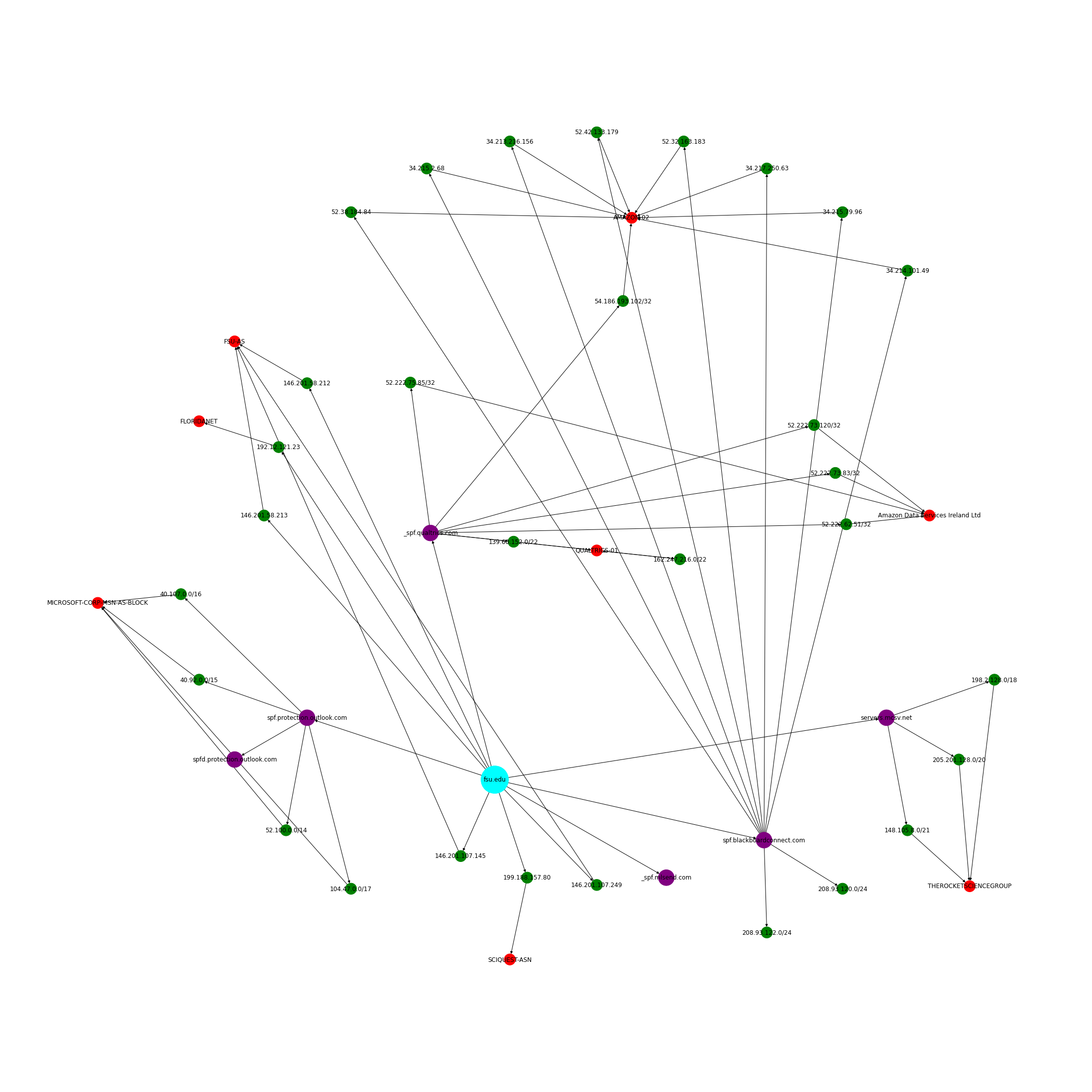
Step Two: Enrichment
For this step, I reused a lot of the code from my previous blog post on Mining MX records and performed the following enrichments:
- Maxmind ASN
- Maxmind Country
- Cloud Provider IP Lookups for AWS, Azure, and GCP
- Alexa Ranking
- Email Security Provider mapping
netaddr, tldextract, and cidr-trie were useful during this stage.
Step Three: Analysis
Through this analysis, I hoped to answer the following questions:
- What is the largest trusted network size (both single CIDR and aggregate network space)? … HUGE
- Could I find any blatantly misconfigured SPF records? … YES
- What does SPF data show about email security providers? … A lot that MX doesn’t
- What are the most “included” SPF includes? … Not many surprises here
- Does SPF augment the MX record mining (give more coverage? reveal things previously hidden? or 100% redundant?) … YES!
- Are domains trusting IP space from cloud providers that may be re-usable (i.e. AWS EC2)? … YES!
Below are some outputs and commentary from this project’s Jupyter notebook that answer the questions above.
Network Graphs
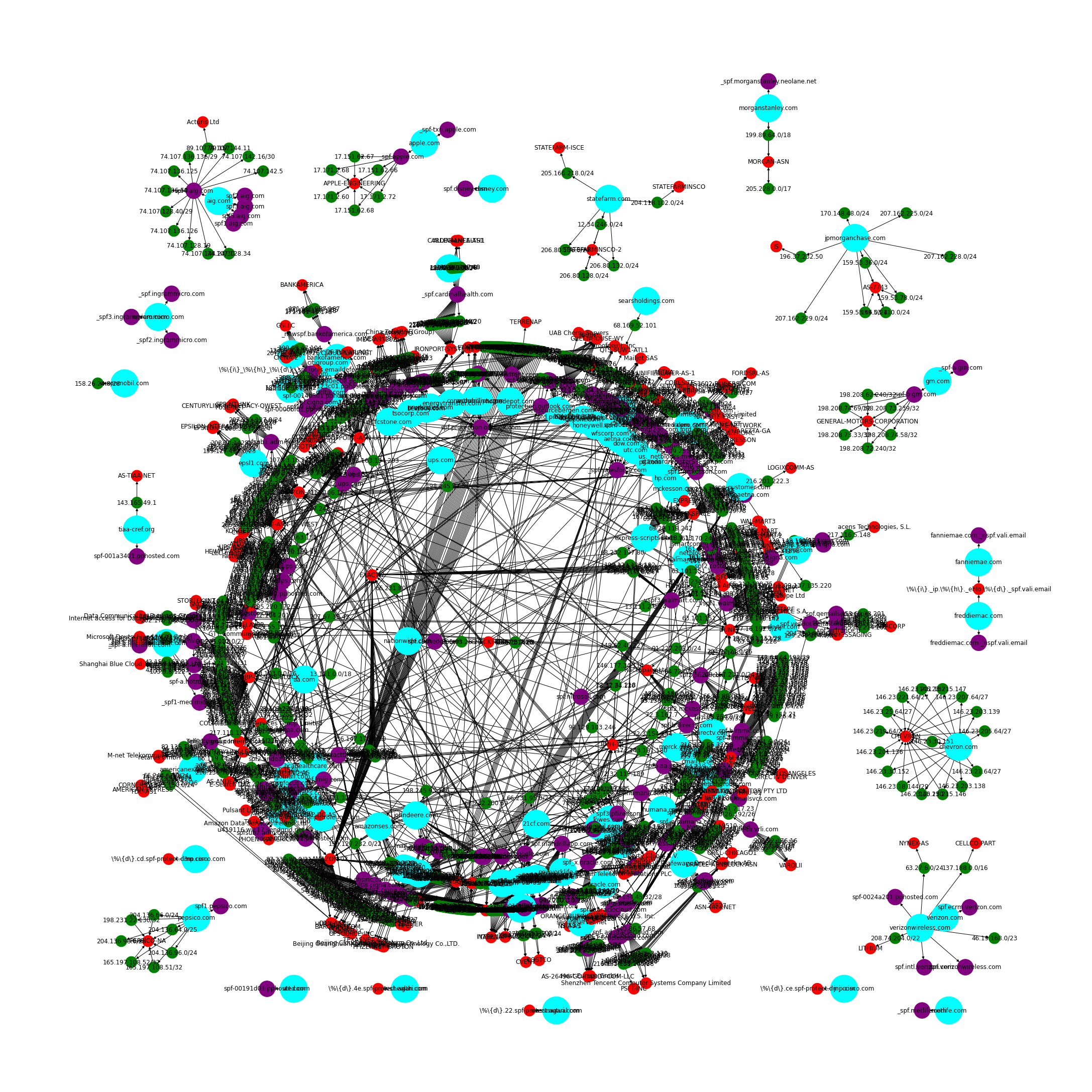
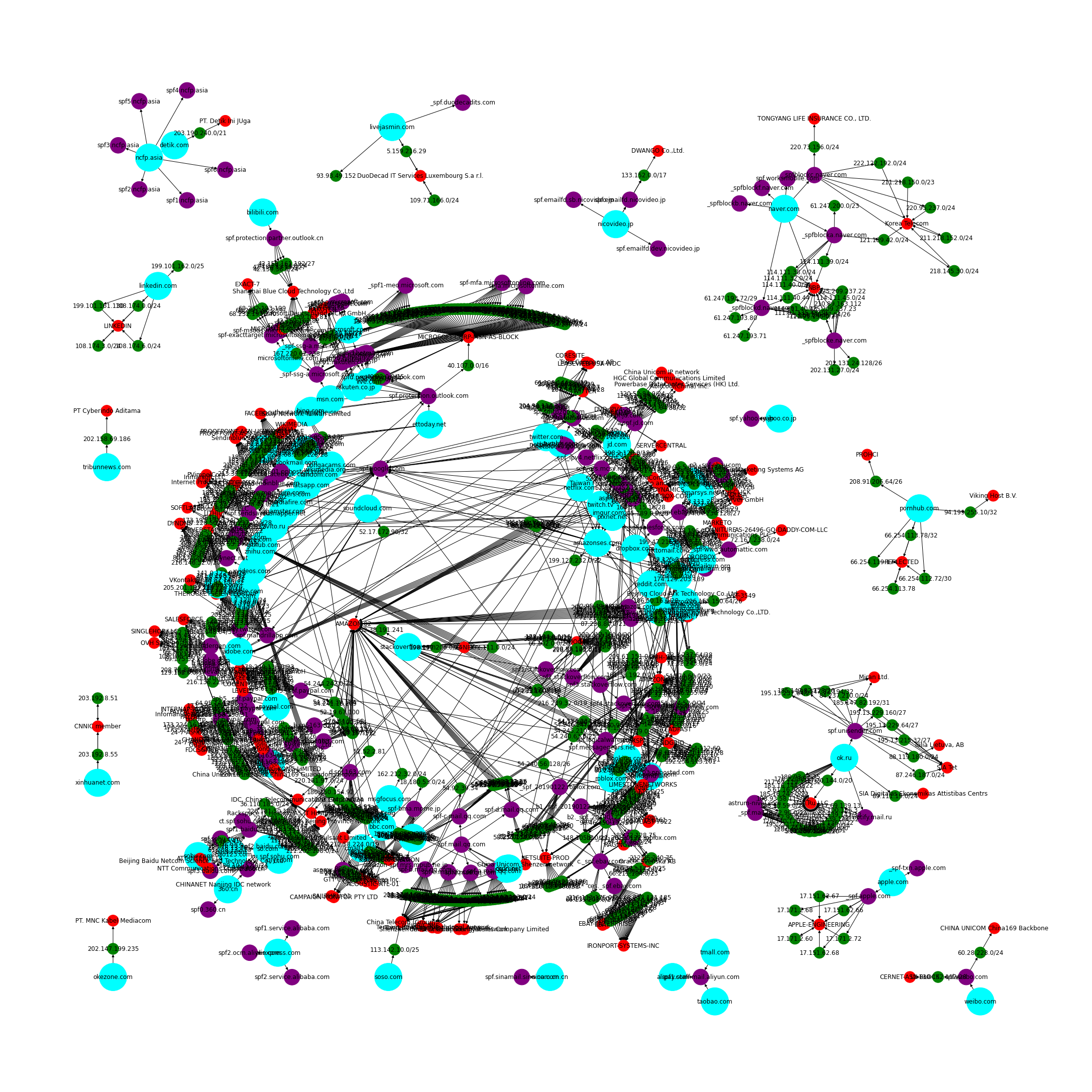
These networkx visualizations of the Fortune 100 and Alexa 100 are a bit of a mess, but they should get the point across of how interconnected the SPF trust relationships are.
Fortune 100 SPF Trusted Networks Graph
Alexa 100 SPF Trusted Networks Graph
Heatmaps
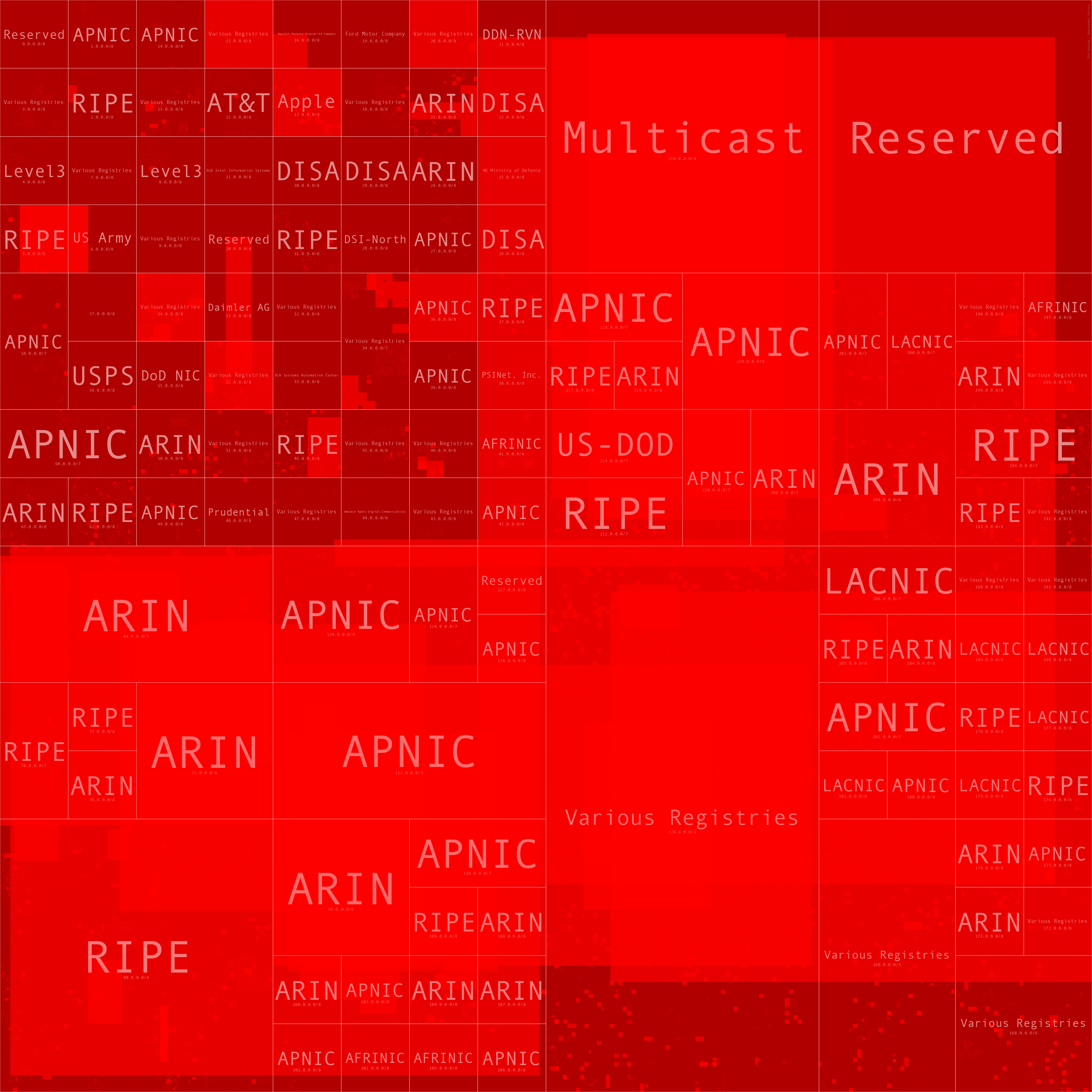
As you can see from the next several heatmaps, as we go beyond the Alexa top 1,000 domains the number of networks trusted drastically increases, and as we hit the Alexa 1m, the entire Internet is trusted (likely due to SPF misconfigurations).
These heatmaps were generated with the awesome ipv4-heatmap tool provided by the Measurement Factory. The code to automate this can be found in my Jupyter Notebook here.
Fortune 1,000 SPF Trusted Networks Heatmap

Alexa 1,000 SPF Trusted Networks Heatmap

Alexa 10,000 SPF Trusted Networks Heatmap

Alexa 100,000 SPF Trusted Networks Heatmap
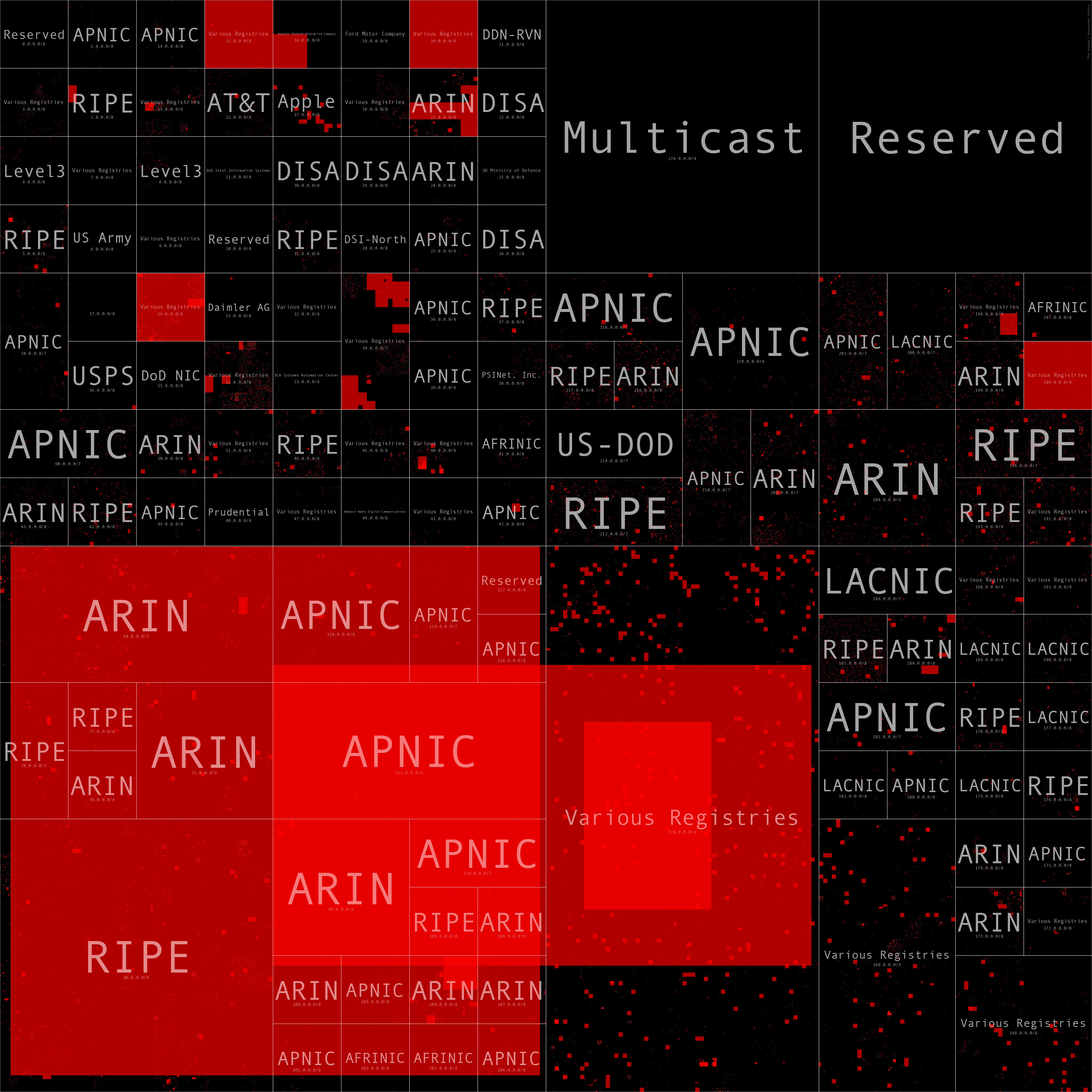
Alexa 1,000,000 SPF Trusted Networks Heatmap
Alexa Top 1M Domains Trusting /7 or larger networks
As you can see from this list, there are quite a few domains that trust very large networks. Several of these seem like likely misconfigurations. For example, these four domains trust the entire Internet:
- hitadouble[.]com: 208.67.207.0/0
- payukraine[.]com: 0.0.0.0/0
- angliss[.]edu[.]au: 0.0.0.0/0
- hutkigrosh[.]by: 0.0.0.0/0
This domain trusts half of the Internet - salaam[.]af: 175.106.32.0/1
And these five domains trust 1/4 of the Internet. cfe[.]fr appears to have fixed this apparent misconfiguration now. As their TXT record has changed.
- creativecircle[.]com: 64.4.22.64/2
- gevestor[.]de: 91.241.72.0/2
- debeersgroup[.]com: 10.47.149.168/2
- cfe[.]fr: 82.97.62.0/2
- adecco[.]com: 148.105.8.0/2
Top SPF Includes from all top domain lists (via SPF)
Using all the popular domain names, here is a summary of the top 10 SPF includes.
Major Cloud Email Providers:
- Microsoft: spf.protection.outlook.com
- Google: _spf.google.com
Hosting Providers:
- HostGator: websitewelcome.com
- OVH: mx.ovh.com
- Bluehost: bluehost.com
Commercial Email Marketing companies
- MailChimp: servers.mcsv.net
- Mandrill: spf.mandrillapp.com (MailChimp add-on)
- Sendgrid: sendgrid.net
Email Security company:
- MailChannels: mailchannels.net (more on this later)
Top SPF Includes from Fortune 1000 (via SPF)
Top SPF Includes from Alexa top1m
Email Security Providers
If you read my previous blog post on Mining DNS MX Records for Fun and Profit, then you might notice that these top lists look significantly different than the top email providers as identified from MX records. The top 5 providers identified in the SPF data are MailChannels, Mimecast, Proofpoint, Solarwinds, and Barracuda. In the MX post, the top 5 were Proofpoint, Mimecast, Deteque, Barracuda, and Solarwinds, AND MailChannels was #48 on that list. These top lists are using all the popular domains data which is likely not an accurate reflection of the actual email security market. When reviewing the Fortune 1000 top Email Security providers the story is not as surprising as the top 4 from the Fortune 1000 Email security providers were nearly identical across SPF and MX records with just the order being different. I suspect that MailChannels shows up as popular in SPF because either it is the default setting on newly registered domains OR it is the default setting for domains that are parked with certain hosting providers, but I haven’t spent the time to prove/disprove this.
(Update 7/7/2020) I received this message from Ken Simpson, CEO of MailChannels, that helps explain why there is a mismatch between the MX and SPF counts.
“You were wondering why MailChannels shows up in a lot of SPF records (actually, we’re number one), but relatively few MX records. MailChannels delivers email for the web hosting industry, with over 700 service provider customers worldwide. To deliver email reliably, they have to add us to their customers’ SPF records. Those same customers often host their inbound email with someone else - GSuite, Microsoft 365, or another provider. Hence the mismatch in SPF and MX records.”
One other interesting aspect with SPF is it (potentially) reveals relationships with multiple email security providers. See the “Fortune 100 Email Security Providers Listing (via SPF)” and “Domains with 4 or more Email Security Providers (via SPF)” gists below. In the Fortune 100 list, there are 3 domains with SPF relationships with more than one provider. If you look across all the top domains data you can see there are many. For anyone who has worked in the cyber security department at a large company before, this is not surprising, but it was cool to be able to see this in the data.
- Domains with 2 SPF relationships with Email Security Providers: 11,393
- Domains with 3 SPF relationships with Email Security Providers: 468
- Domains with 4 SPF relationships with Email Security Providers: 35
- Domains with 5 SPF relationships with Email Security Providers: 1
Top Email Security Provider from all top domain lists (via SPF)
Top Email Security Provider from Alexa 1m (via SPF)
Top Email Security Provider from Fortune 1000 (via SPF)
Top Email Security Provider from Fortune 100 (via SPF)
Fortune 100 Email Security Providers Listing (via SPF)
Domains with 4 or more Email Security Providers (via SPF)
Trusting Cloud Provider Networks
As you can see from the next few tables, many domains transitively trust a lot of Cloud provider IP space for SPF. For some of the larger networks trusted it seems like this carries risk since it may be possible for the cloud IP space to get reused; see Fishing the AWS IP Pool for Dangling Domains for a practical example of this. Like I mentioned earlier, SPF is usually used with DKIM and DMARC so this data doesn’t paint the whole picture. I am hoping to dive into DMARC/DKIM next.
Alexa 1000 Trusting AWS Networks
Alexa 1000 Trusting Azure Networks
Alexa 1000 Trusting GCP Networks
Fortune 1000 Trusting AWS Networks
Fortune 1000 Trusting Azure Networks
Fortune 1000 Trusting GCP Networks
Some other potentially interesting results, not worth dumping here:
- Alexa top1m domains trusting AWS Networks
- Alexa top1m domains trusting Azure Networks
- Alexa top1m domains trusting GCP Networks
- Top Maxmind ASNs of SFP Trusted Networks from Fortune 1000 (via SPF)
- Top Maxmind ASNs of SFP Trusted Networks from all top domain lists (via SPF)
- Top Maxmind ASNs of SFP Trusted Networks from Alexa top1m (via SPF)
- Graph analytics applied to Fortune 1000 and Alexa 1000: degree centrality, edge betweenness centrality, pagerank, closeness centrality, triangle counts, and connected components stats, see the notebook and search for “print_graph_metrics”.
Future Work
- SPF Crawler enhancements: As you can see from the SPF guide I shared above for “a” and “mx”, SPF supports some fairly complex policies for allowing certain IPs to send email (esp. the prefix operators on these SPF mechanisms). I did not provide support for these mechanisms in the first version of my SPF crawler mainly due to the complexity involved. Because of this, my results will under represent the trust relationships where these are used. I hope to add support for these operators to expand what could be found in this data.
- Try some more graph analytics on the entire dataset. In the Jupyter notebook I ran several graph algorithms on subsets of the entire graph (Fortune 100 and Alexa 100). These showed some mildly interesting results, but testing against larger graphs caused graphviz to fail due to some data format issues that I have not had a chance to research.
- Perform another study measuring DMARC and DKIM usage across popular domains.
Resources
As usual all notebooks, code, and summary results can be found in Github: https://github.com/covert-labs/mx-intel.
And all data can be found at the links below:
- all-registered-domains.txt.gz - base domains extracted from combining several popular domains lists together and then uniqued.
- all-registered-domains-outputs-combined.txt.gz - raw dig output for all the TXT requests.
- spf-results-all-registered-domains.json.gz - the parsed results from running the SPF Crawler against all-registered-domains.txt.gz.
- spf-linked-all-registered-domains.json.gz - the assembled results from processing spf-results-all-registered-domains.json.gz. This is the collapsed/combined data that shows all the SPF domains and networks included recursively.
–Jason
@jason_trost