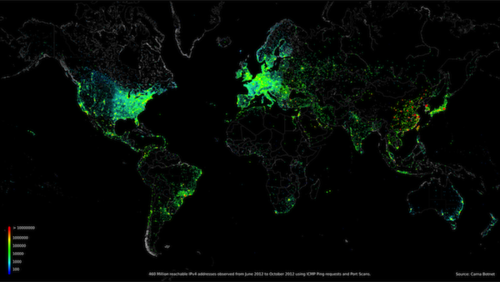
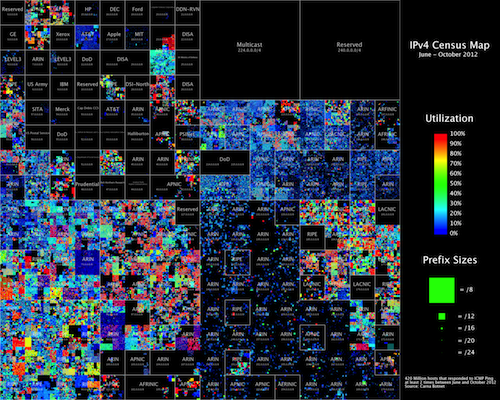
This is another quick post. I have been working on this small framework for a while now and I decided to publish the code before I completely finished.
The hadoop-dns-mining framework enables large scale DNS lookups using Hadoop. For example, if you had access to zone files from COM, NET, ORG, etc (all free and publicly available), you could take each domain in these files and use this framework to resolve the domains for various record types (A, AAAA, MX, TXT, NS, etc). After resolving the domains, you can run them through an enrichment process to add city, county, lat, long, ASN, and AS Name (via Maxmind’s DBs). And, you could scale out this collection and processing effort using Hadoop, say, running over EC2.
There are some interesting applications of this type of system, like using the existing zone files names to brute force “generating” zone files for TLDs that do not publish them (most ccTLDs do not). For example, like this company has done: http://viewdns.info/data/
For more details check out my github repo. The README covers DNS collection and geo enrichment. I have code checked in that will store this data in Accumulo using a few different storage/access patterns, but more explanation will come later as I have time.
https://github.com/jatrost/hadoop-dns-mining
–Jason
@jason_trost