
In this post I will outline the steps necessary to use Accumulo and Gora to store content retrieved by Nutch.
###Apache Accumulo
![]()
For those of you unfamiliar with Accumulo, it is an incubating Apache project and …
“Accumulo is a sorted, distributed key/value store based on Google’s BigTable design. It is built on top of Apache Hadoop, Zookeeper, and Thrift. It features a few novel improvements on the BigTable design in the form of cell-level access labels and a server-side programming mechanism that can modify key/value pairs at various points in the data management process.”
Accumulo is conceptually very similar to HBase, but it has some nice features that HBase is currently lacking. Some of these features are:
- Cell level security
- No fat row problem - i.e. entire rows don’t need to fit in RAM
- No limitation on Column Families or when Column Families can be created
- Server side, data local, programming abstraction called Iterators. Iterators are incredibly useful for adding functionality to Tablet Servers such as data local filtering, aggregation, and search.
- Check out this example application that shows off some of the features mentioned above: THE WIKIPEDIA SEARCH EXAMPLE EXPLAINED, WITH PERFORMANCE NUMBERS.
###Apache Gora
![]()
Gora is a object relational/non-relational mapping for arbitrary data stores including both relational (MySQL) and non-relational data stores (HBase, Cassandra, Accumulo, etc). It was designed for Big Data applications and has support (interfaces) for Apache Pig, Apache Hive, Cascading, and generic Map/Reduce.
Apache Nutch
![]()
Nutch is a highly scalable web crawler built over Hadoop Map/Reduce. It was designed from the ground up to be an Internet scale web crawler. This is a great overview of Nutch’s architecture: Nutch as a Web Data Mining Platform
###Accumulo + Nutch + Gora
I generally prefer git over svn, in this post I use the source code hosted on github.
####1. Obtain all sources (and Accumulo patch for GORA)
git clone git://github.com/apache/nutch.git
git clone git://github.com/apache/gora.git
git clone git://github.com/apache/accumulo.git
wget https://issues.apache.org/jira/secure/attachment/12507986/GORA-65-1.patch####2. Configure and Build Each Project:
#####Standard build and maven install for accumulo
cd accumulo
mvn package install#####Patching GORA for Accumulo Support
Gora needs to be patched for support for Accumulo. This patch should be considered beta, but I found it works good enough for experimenting with Nutch/GORA. Note: 1
-DskipTests
cd ../gora
patch -p0 < ../GORA-65-1.patch
mvn package install -DskipTests#####Building Nutch/GORA
So, getting Nutch/GORA to build was a bit of a challenge. I will outline some of the hoops I had to jump through. File paths mentioned below are assuming you are in the nutch project directory.
Run the following commands to checkout the nutchgora branch of Nutch.
cd ../nutch
git checkout origin/nutchgora- Modify the
1
ivy/ivy.xml
1
"0.1.1-incubating"
1
"0.2-SNAPSHOT"
<dependency org="org.apache.accumulo" name="accumulo-core" rev="1.5.0-incubating-SNAPSHOT" />
<dependency org="org.apache.accumulo" name="cloudtrace" rev="1.5.0-incubating-SNAPSHOT" />
<dependency org="org.apache.thrift" name="libthrift" rev="0.6.1" />
<dependency org="org.apache.gora" name="gora-accumulo" rev="0.2-SNAPSHOT" />
<dependency org="org.apache.zookeeper" name="zookeeper" rev="3.4.3" />- Modify the
1
ivy/ivysettings.xml
1
<resolvers>
<ibiblio name="local" root="file://${user.home}/.m2/repository/"
pattern="${maven2.pattern.ext}" m2compatible="true" />- Patch
src/java/org/apache/nutch/storage/StorageUtils.java - Create the file
conf/gora-accumulo-mapping.xmlwith the following contents: - Edit
conf/gora.propertiesand add the following lines: - edit (or create)
conf/nutch-site.xmland adding the following property setting to it - edit $HOME/.ivy2/cache/jaxen/jaxen/ivy-1.1.3.xml and find and comment out the following lines. If anyone knows a more elegant way to accomplish this please let me know.
- Run the following commands:
diff --git a/src/java/org/apache/nutch/storage/StorageUtils.java b/src/java/org/apache/nutch/storage/StorageUtils.java
index de740b5..19b37ad 100644
--- a/src/java/org/apache/nutch/storage/StorageUtils.java
+++ b/src/java/org/apache/nutch/storage/StorageUtils.java
@@ -40,8 +40,9 @@ public class StorageUtils {
Class<K> keyClass, Class<V> persistentClass) throws ClassNotFoundException, GoraException {
Class<? extends DataStore<K, V>> dataStoreClass =
(Class<? extends DataStore<K, V>>) getDataStoreClass(conf);
+
return DataStoreFactory.createDataStore(dataStoreClass,
- keyClass, persistentClass);
+ keyClass, persistentClass, conf);
}
@SuppressWarnings("unchecked")
@@ -56,8 +57,9 @@ public class StorageUtils {
Class<? extends DataStore<K, V>> dataStoreClass =
(Class<? extends DataStore<K, V>>) getDataStoreClass(conf);
+
return DataStoreFactory.createDataStore(dataStoreClass,
- keyClass, persistentClass, schema);
+ keyClass, persistentClass, conf, schema);
}
@SuppressWarnings("unchecked")<gora-orm>
<table name="webpage">
<config key="table.file.compress.blocksize" value="32K"/>
</table>
<class table="webpage" keyClass="java.lang.String"
name="org.apache.nutch.storage.WebPage">
<!-- fetch fields -->
<field name="baseUrl" family="f" qualifier="bas"/>
<field name="status" family="f" qualifier="st"/>
<field name="prevFetchTime" family="f" qualifier="pts"/>
<field name="fetchTime" family="f" qualifier="ts"/>
<field name="fetchInterval" family="f" qualifier="fi"/>
<field name="retriesSinceFetch" family="f" qualifier="rsf"/>
<field name="reprUrl" family="f" qualifier="rpr"/>
<field name="content" family="f" qualifier="cnt"/>
<field name="contentType" family="f" qualifier="typ"/>
<field name="protocolStatus" family="f" qualifier="prot"/>
<field name="modifiedTime" family="f" qualifier="mod"/>
<!-- parse fields -->
<field name="title" family="p" qualifier="t"/>
<field name="text" family="p" qualifier="c"/>
<field name="parseStatus" family="p" qualifier="st"/>
<field name="signature" family="p" qualifier="sig"/>
<field name="prevSignature" family="p" qualifier="psig"/>
<!-- score fields -->
<field name="score" family="s" qualifier="s"/>
<field name="headers" family="h"/>
<field name="inlinks" family="il"/>
<field name="outlinks" family="ol"/>
<field name="metadata" family="mtdt"/>
<field name="markers" family="mk"/>
</class>
</gora-orm>gora.datastore.default=org.apache.gora.accumulo.store.AccumuloStore
gora.datastore.accumulo.mock=false
gora.datastore.accumulo.instance=inst
gora.datastore.accumulo.zookeepers=localhost
gora.datastore.accumulo.user=root
gora.datastore.accumulo.password=secret
gora.datastore.accumulo.zookeepers=127.0.0.1:2181<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>storage.data.store.class</name>
<value>org.apache.gora.accumulo.store.AccumuloStore</value>
</property>
<property>
<name>http.agent.name</name>
<value>Nutch</value>
</property>
</configuration><!-- <dependency org="maven-plugins" name="maven-cobertura-plugin" rev="1.3" force="true" conf="compile->compile(*),master(*);runtime->runtime(*)">
<artifact name="maven-cobertura-plugin" type="plugin" ext="plugin" conf=""/>
</dependency>
<dependency org="maven-plugins" name="maven-findbugs-plugin" rev="1.3.1" force="true" conf="compile->compile(*),master(*);runtime->runtime(*)">
<artifact name="maven-findbugs-plugin" type="plugin" ext="plugin" conf=""/>
</dependency>
-->[ivy:resolve] ::::::::::::::::::::::::::::::::::::::::::::::
[ivy:resolve] :: FAILED DOWNLOADS ::
[ivy:resolve] :: ^ see resolution messages for details ^ ::
[ivy:resolve] ::::::::::::::::::::::::::::::::::::::::::::::
[ivy:resolve] :: maven-plugins#maven-cobertura-plugin;1.3!maven-cobertura-plugin.plugin
[ivy:resolve] :: maven-plugins#maven-findbugs-plugin;1.3.1!maven-findbugs-plugin.plugin
[ivy:resolve] ::::::::::::::::::::::::::::::::::::::::::::::ant
####3. Deploy and Run
#####Configure Accumulo and its Dependencies
For this post I am only going to cover the basics for getting these systems to run on a single machine. Deploying and running over a cluster may be covered in another post.
######Configure and Start Hadoop
cd ..
wget ftp://apache.cs.utah.edu/apache.org//hadoop/common/hadoop-0.20.2/hadoop-0.20.2.tar.gz
tar zxvf hadoop-0.20.2.tar.gzAdd the following to 1
hadoop-0.20.2/conf/core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/${user.name}/tmp/hadoop</value>
</property>
</configuration>Add the following to 1
hadoop-0.20.2/conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>127.0.0.1:9001</value>
</property>
</configuration>Set the JAVA_HOME variable in 1
hadoop-0.20.2/conf/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26At this point, you should have a bare bones configured hadoop installation. It is time to start it…
Run the following commands:
mkdir -p ~/tmp/hadoop
cd hadoop-0.20.2
./bin/hadoop namenode -format
./bin/start-all.shIf you configured everything properly, you should be able to open http://127.0.0.1:50070/dfshealth.jsp in a web browser and see a page that looks like this. If there is a message saying that the Namenode is in safe mode, wait a minute or two and refresh the page. It should go away.
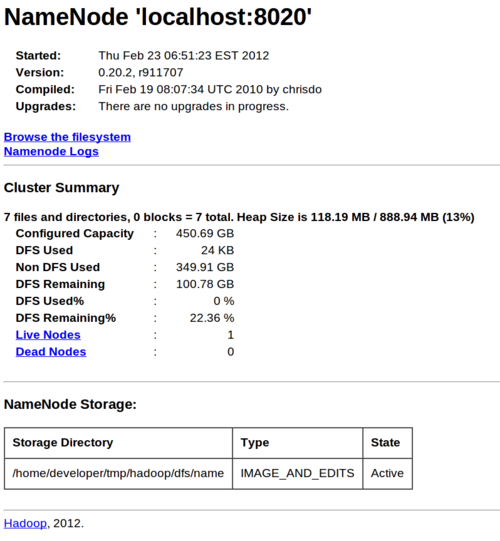
You should also be able to open http://127.0.0.1:50030/jobtracker.jsp in a web browser and see a page that looks like this:
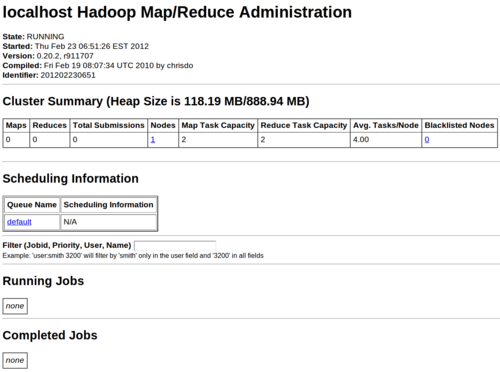
In both of these status webpages you should be able to see a 1
1
1
"Live Nodes"
1
"Nodes"
######Configure and Start Zookeeper
cd ..
wget ftp://apache.cs.utah.edu/apache.org/zookeeper/zookeeper-3.4.3/zookeeper-3.4.3.tar.gz
tar zxvf zookeeper-3.4.3.tar.gzAdd the following to 1
zookeeper-3.4.3/conf/zoo.cfg
1
_USERNAME_
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
dataDir=/home/_USERNAME_/tmp/zookeeper-data
# the port at which the clients will connect
clientPort=2181
maxClientCnxns=100Edit bin/zkEnv.sh. Right after the following lines.
ZOOBINDIR=${ZOOBINDIR:-/usr/bin}
ZOOKEEPER_PREFIX=${ZOOBINDIR}/..Add this line:
export ZOO_LOG_DIR=${ZOOKEEPER_PREFIX}/logscd zookeeper-3.4.3
export ZOO_LOG_DIR=$HOME/blogpost/zookeeper-3.4.3/logs
mkdir $ZOO_LOG_DIR
mkdir ~/tmp/zookeeper-dataAt this point, you should have a configured zookeeper installation, it’s time to start it…
./bin/zkServer.sh startIf you configured zookeeper and it successfully started you should be able to run the following command:
./bin/zkCli.sh -server 127.0.0.1:2181It will output a bunch of logging messages, this is fine. Press 1
<ENTER>
[zk: 127.0.0.1:2181(CONNECTED) 0]Type 1
ls /
1
<ENTER>
[zookeeper]If so, then zookeeper is configured and running properly. When you first run the zkCli.sh command, if you see stack traces that look like this:
java.net.ConnectException: Connection refused
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:701)
at org.apache.zookeeper.ClientCnxnSocketNIO.doTransport(ClientCnxnSocketNIO.java:286)
at org.apache.zookeeper.ClientCnxn$SendThread.run(ClientCnxn.java:1035)Then it means zookeeper failed to start for some reason, isn’t listening on 127.0.0.1:2181, or you may have a local firewall blocking access to that port.
######Configure and Start Accumulo
cd ../accumulo
mvn package -P assemble
cp src/assemble/target/accumulo-1.5.0-incubating-SNAPSHOT-dist.tar.gz ../
cd ../
tar zxf accumulo-1.5.0-incubating-SNAPSHOT-dist.tar.gz
cd accumulo-1.5.0-incubating-SNAPSHOT/conf
rename s/.example// *.example
# basically disabling the custom security policy file for now
# since I had issues getting accumulo to work with it enabled
mv accumulo.policy accumulo.policy.example Edit 1
accumulo-env.sh
export HADOOP_HOME=$HOME/hadoop-0.20.2
export ZOOKEEPER_HOME=$HOME/zookeeper-3.4.3
export JAVA_HOME=/usr/lib/jvm/java-6-sun-1.6.0.26Edit 1
accumulo-site.xml
Set the 1
logger.dir.walog
<property>
<name>logger.dir.walog</name>
<value>$HOME/tmp/walogs</value>
</property>Set the 1
instance.secret
<property>
<name>instance.secret</name>
<value>SOME-PASSWORD-OF-YOUR-CHOOSING</value>
</property>Run the following commands:
mkdir $HOME/tmp/walogs
cd ../At this point you should have a fully configured Accumulo installation. It is time to initialize it and start it…
./bin/accumulo initYou should see similar output to this. I set my instance name to 1
"inst"
1
"secret"
23 08:15:26,635 [util.Initialize] INFO : Hadoop Filesystem is hdfs://127.0.0.1/
23 08:15:26,637 [util.Initialize] INFO : Accumulo data dir is /accumulo
23 08:15:26,637 [util.Initialize] INFO : Zookeeper server is localhost:2181
Warning!!! Your instance secret is still set to the default, this is not secure.
We highly recommend you change it.
You can change the instance secret in accumulo by using: bin/accumulo
org.apache.accumulo.server.util.ChangeSecret oldPassword newPassword.
You will also need to edit your secret in your configuration file by adding the property
instance.secret to your conf/accumulo-site.xml. Without this accumulo will not operate correctly
Instance name : inst
Enter initial password for root: ******
Confirm initial password for root: *****
23 08:15:34,100 [util.NativeCodeLoader] INFO : Loaded the native-hadoop library
23 08:15:34,337 [security.ZKAuthenticator] INFO : Initialized root user with
username: root at the request of user !SYSTEMNote: If it appears to hang after you entered the instance name, zookeeper may not be running. 1
<CTRL>-C
Now run:
./bin/start-all.shAfter this finishes, you should be able to open http://127.0.0.1:50095/ in a web browser and see a page very similar to this:
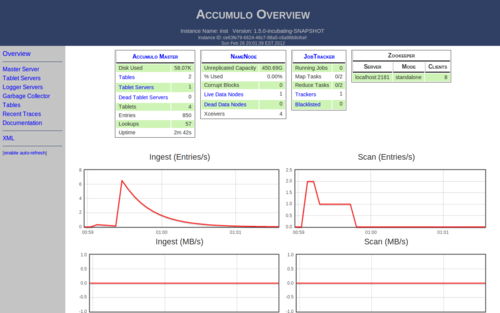
The important items to note on this page are the is a 1 after the Tablet Servers, Live Data Nodes, and Trackers in the “Accumulo Master”, “NameNode”, and “JobTracker” tables, respectively. There should also be entry in the “Zookeeper” table.
###4. Crawl
At this point, you should have a fully functional Hadoop, Zookeeper, and Accumulo install, so we are ready to run a Nutch web crawl. Create a file with URLs, one per line, call it seeds.txt and place it in your home directory. I added the following URLs to my seeds file:
http://projects.apache.org/indexes/alpha.html
http://www.dmoz.org/Arts/People/Run the following commands:
cd ../nutch/
./runtime/local/bin/nutch crawl file://$HOME/seeds.txt -depth 1You should see some log messages printed to the console, but hopefully no stack traces. If you see a stack trace, you may need to go back and check your configs to make sure they match the ones we created earlier.
After the crawler finishes, you should be able to explore it using the accumulo shell.
cd ../accumulo-1.5.0-incubating-SNAPSHOT/bin/
./accumulo shell -u root -p secretShell - Accumulo Interactive Shell
-
- version: 1.5.0-incubating-SNAPSHOT
- instance name: inst
- instance id: ce63fe79-6624-46c7-98a5-c6a98b8cfcef
-
- type 'help' for a list of available commands
-
root@inst> table webpage
root@inst webpage> scan
org.apache.projects:http/categories.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/categories.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/categories.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x90
org.apache.projects:http/categories.html il:http://projects.apache.org/indexes/alpha.html [] Categories
org.apache.projects:http/categories.html mk:_gnmrk_ [] 1330427514-1313139543
org.apache.projects:http/categories.html mtdt:_csh_ [] <\x16O\xDA
org.apache.projects:http/categories.html s:s [] <\x16O\xDA
org.apache.projects:http/create.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/create.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/create.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x92
org.apache.projects:http/create.html il:http://projects.apache.org/indexes/alpha.html [] Create a DOAP File
org.apache.projects:http/create.html mk:_gnmrk_ [] 1330427514-1313139543
org.apache.projects:http/create.html mtdt:_csh_ [] <\x16O\xDA
org.apache.projects:http/create.html s:s [] <\x16O\xDA
org.apache.projects:http/doap.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/doap.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/doap.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x92
org.apache.projects:http/doap.html il:http://projects.apache.org/indexes/alpha.html [] DOAP Files
org.apache.projects:http/doap.html mk:_gnmrk_ [] 1330427514-1313139543
org.apache.projects:http/doap.html mtdt:_csh_ [] <\x16O\xDA
org.apache.projects:http/doap.html s:s [] <\x16O\xDA
org.apache.projects:http/doapfaq.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/doapfaq.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/doapfaq.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x93
org.apache.projects:http/doapfaq.html il:http://projects.apache.org/indexes/alpha.html [] DOAP File FAQ
org.apache.projects:http/doapfaq.html mk:_gnmrk_ [] 1330427514-1313139543
org.apache.projects:http/doapfaq.html mtdt:_csh_ [] <\x16O\xDA
org.apache.projects:http/doapfaq.html s:s [] <\x16O\xDA
org.apache.projects:http/docs/dependancies.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/docs/dependancies.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/docs/dependancies.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x94
org.apache.projects:http/docs/dependancies.html il:http://projects.apache.org/indexes/alpha.html [] Dependencies
org.apache.projects:http/docs/dependancies.html mk:_gnmrk_ [] 1330427514-1313139543
org.apache.projects:http/docs/dependancies.html mtdt:_csh_ [] <\x16O\xDA
org.apache.projects:http/docs/dependancies.html s:s [] <\x16O\xDA
org.apache.projects:http/docs/index.html f:fi [] \x00'\x8D\x00
org.apache.projects:http/docs/index.html f:st [] \x00\x00\x00\x01
org.apache.projects:http/docs/index.html f:ts [] \x00\x00\x015\xC3\xA8\xCD\x96Further details and exploration of this data in Accumulo will have to wait for another blog post.
I ended up posting all the modified code from Gora (accumulo patch) and Nutchgora (patches for getting gora-accumulo working) to my github. Check it out.
Let me know if you have any questions…
–Jason
@jason_trost
Update (3/2): someone told me that they had problems getting nutch to build and that this patch worked for them (even though the patch is for GORA). I would be curious if anyone else has this same issue. Here is the error they encountered when building with 1
ant
[ivy:resolve] :: problems summary ::
[ivy:resolve] :::: WARNINGS
[ivy:resolve] ::::::::::::::::::::::::::::::::::::::::::::::
[ivy:resolve] :: UNRESOLVED DEPENDENCIES ::
[ivy:resolve] ::::::::::::::::::::::::::::::::::::::::::::::
[ivy:resolve] :: log4j#log4j;1.2.15: configuration not found in log4j#log4j;1.2.15: 'master'.